
Databasens historie
Den moderne database har rødder tilbage i 1960erne takket være bl.a. IBM. I 1970 udgav Edgar “Ted” Codd, der også var ansat ved IBM, en artikel der beskriver en relationel database1. Han lagde senere navn til en af normal-formerne2.
IBM var dog langsomme til at implementere den relationelle database, og lavede således det ikke-relationelle sprog SEQUEL, der var så godt at det allerede inden udgivelse blev kopieret og brugt i Oracle Database3 af Larry Ellison4 og navnet blev skiftet til SQL.
SQL blev en ANSI standard i 1986 og ISO i 1987, og selv om der i dag findes mange mere eller mindre proprietære implementeringer er det grundlæggende sprog universelt mellem mange database systemer.
SQL
Langt de fleste relational database management systemer (RDMS), som er hvad de fleste forbinder med betegnelsen database, bruger sproget SQL (structured query language) til at behandle og manipulere data.
I SQL er tabeller og forespørgsels-resultater lister over rækker: den samme række kan forekomme flere gange, og rækkefølgen af rækker kan anvendes i forespørgsler (f.eks. ved LIMIT).
SQL er opdelt i flere elementer:
- Klausuler (clauses), der er konstituerende bestanddele af erklæringer og forespørgsler – i nogle tilfælde valgfri.
- Udtryk (expressions), der kan producere enten skalar værdier, eller tabeller, der består af kolonner og rækker af data.
- Prædikater (predicates), der angiver betingelser, der kan evalueres til SQL tre-værdi logik (3VL) (sandt / falsk / ukendt)5 eller Boolske værdier6, som anvendes til at begrænse virkningerne af erklæringer og forespørgsler, eller til at ændre programmets flow.
- Forespørgsler (queries), henter og sender data baseret på specifikke kriterier. Dette kan betegnes som essensen af SQL.
- Udsagn (statements), som kan have en vedvarende effekt på skemaer (schema, samling af database objekter, typisk tabeller) og data, eller som kan kontrollere transaktioner, programmets flow, forbindelser, sessioner, eller diagnostik.
- SQL-sætninger benytter semikolon (“;”) terminatoren. Selv om det ikke kræves på alle platforme, det er defineret som en standard del af SQL-grammatik.
- Ubetydelige mellemrum er generelt ignoreret i SQL-sætninger og forespørgsler, hvilket gør det let at formatere SQL kode læsbart.
Queries
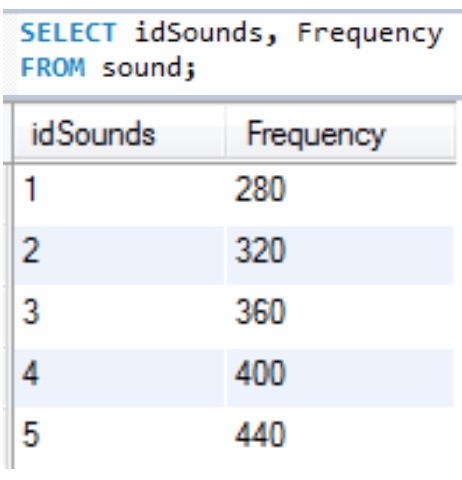
I SQL anvendes queries til SELECT, INSERT, UPDATE og DELETE data fra en database. Længden af en query kan variere efter hvor mange tabeller man arbejder med.
I SQL er der mange reserverede ord, flere af dem kan ikke anvendes som tabel navne f.eks. kan man ikke kalde en tabel for “table”, “drop” eller “delete”. Reserverede ord er typisk angivet med blå tekst i en query og det vil være en fordel at undgå disse reserverede ord som tabel- og kolonne navne.
Man kan kombinere informationer fra flere tabeller ved hjælp af Join.
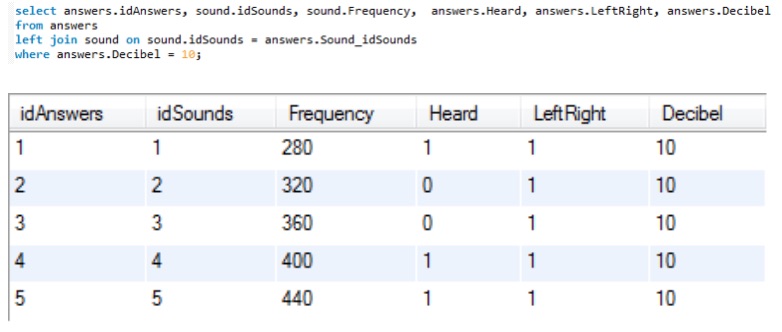

Joins
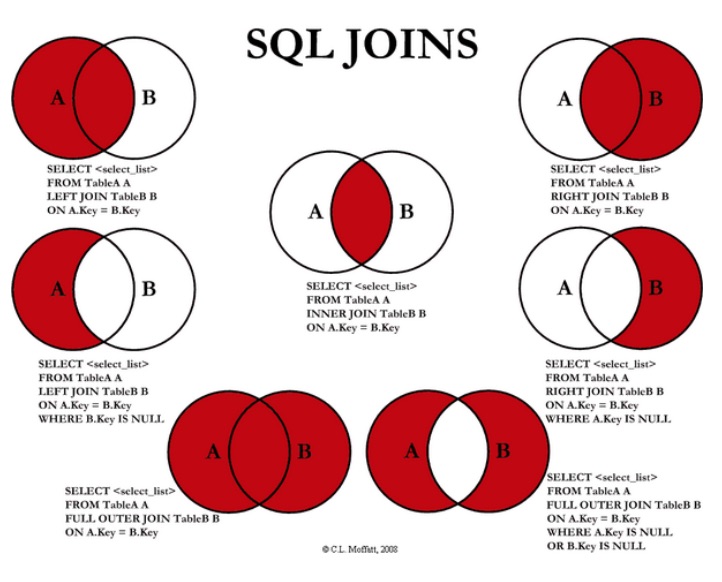
I SQL bruges JOIN til at sætte en eller flere tabeller sammen i et resultat sæt. Der findes forskellige slags joins, der sætter tabellerne sammen på forskellige måder.
Inner join kombinere to tabeller og tilslutter dem sammen baseret på kolonnerne i tabellen. Ved brug af inner join angiver man hvilke kolonner man ønsker at sætte sammen og under hvilken tilstand (condition). INNER delen i INNER JOIN er valgfrit i de fleste database systemer, da inner joins er standard, fordi det er det meste benyttede. Det vil sige man kan nøjes med at bruge JOIN som kommando 7.
Ved inner join sættes alle værdier, der passer sammen, sammen, men ved Outer join kombineres alle værdier, uanset om de passer sammen eller ej.
Den mest grundlæggende form for join er et Cross join, fordi der ikke bruges ON til at sammensætte tabellerne. I stedet for bliver alle rækker fra tabellen der er nævnt i join’et inkluderet i resultat sættet. 8.
Første række i tabel1 kombineres med alle rækker i tabel2, derefter anden række i tabel1, og sådan fortsættes der gennem alle rækker i tabel1.
Left join og Right join fungerer grundlæggende ligesom Inner join, men ved Left join returneres alle rækker fra venstre tabel og de matchende rækker fra højre tabel. Omvendt ved Right Join, hvor denne returnere alle rækker fra højre tabel og de matchende rækker fra venstre tabel. 9.
Normalformer
Normalisering, brug af normal-former, er systematisk opsætning af data i en database og beskriver afhængighederne og relationerne indholdet imellem.
Ved at normalisere fjerner vi overflødig data og sikrer at der kun er relateret data i en tabel, hvilket både sparer plads og gør database-strukturen mere overskuelig. Samtidig kan adgangen til data bedre begrænses da den er delt op i mere specifikke tabeller, hvilket kan øge sikkerheden 10.
Historien bag normalformerne
Edgar F. Codd, der også “opfandt” relationsmodellen, introducerede Den Første Normal Form i 1970 og anden og tredje form i 1971.
I 1977 føjede Ronald Fagin en Fjerde og en Femte Normal Form til.
Den nyeste tilføjelse af den Sjette Normal Form fra 2002 af C.J. Date, Hugh Darwen og Nikos Lorentzos
Der er andre former ud over disse, f.eks. den tidligere nævnte Boyce Codd Normal Form.
Første normalform
Den første normalform definere at der ikke må være forskellig data i samme felt, hvilket betyder at informationen deles i tabeller efter relation. Ligeledes fjernes gentagne grupper fra individuelle tabeller, hvor hvert sæt af relateret data har en primær-nøgle.
Anden normalform
Her fjernes den redundante data, således sættes værdisæt, der kan bruges til flere poster, i særskilte tabeller.
Tredje normalform
Det der ikke beskriver primærnøglen fjernes nu eller flyttes til andre tabeller.
Esssensen af de første tre normalformer er altså at dataen i tabellen skal beskrive nøglen.
I web-udvikling plejer man normalt kun at gå op i at opfylde de første tre normal-former, da det er de mest essentielle, og de følgende former leder til strukturer der ikke nødvendigvis er optimale til denne brug. Dette ledte til den klassiske huskeregel inspireret af den amerikanske ed ved domstolene: “The data should depend on the key (1NF), the whole key (2NF) and nothing but the key (3NF) (so help me Codd)”.
Fjerde normalform
Her må en tabel ikke have flere en-til-mange og mange-til-en relationer, der ikke direkte hænger sammen og en værdi må ikke have flere afhængigheder. Dette resulterer i en del ekstra tabeller.
Nøglen hører til et id, hvor navnet på nøglen typisk består af id og tabelnavnet.
For at dokumenter vores database som vi har lavet i forbindelse med vores semesterprojekt, har vi lavet et
E/R diagram i MySQL Workbench. Dette er et visuelt værktøj der tillader datamodellering 11. Vores diagram er lavet som et fysisk diagram, der viser tabellernes struktur og deres relationer. Diagrammet repræsenterer nøgler, tabel navne og kolonne navne med dertilhørende data typer. Desuden involveres normaliserings processen (se forrige spalte).
For at optimere vores database laves denne så den følger 3. normalform. Det vil sige at den kun indeholder data, der beskrive primær-nøglen, al data i tabellen omhandler nøglen.
Femte normalform
Alle ikke-trivielle joins skal relatere til primær-nøglen, hvilket betyder at det nogle gange sparer resurser at dele ellers relateret data op. Alle tabeller skal altså kunne bruge * relationer, ellers skal det rykkes ud i ekstra tabeller 12.
Sjette normalform
Den sjette normalform er ret radikal da der ikke må være nogen trivielle join afhængigheder overhovedet. Data deles altså op i flere tabeller hvis den ikke internt relaterer til hinanden.
Den bruges i store datavarehuse og resulterer i rigtig mange tabeller 13, hvoraf de fleste droppes undervejs.
Der er som nævnt i starten af dette afsnit mange flere normal-former, men disse seks er de mest anerkendte.
E/R diagram
Et E/R diagram (entity relationship diagram) er en visuel gengivelse af databasens struktur og hvordan elementerne relaterer til hinanden. Diagrammet illustrerer de forskellige tabeller i databasen, bestående af rækker af kolonner med en dertilhørende primær-nøgle. Primær-nøglen sikrer unik data, da den garanterer at hvert datapunkt har en unik værdi 14, og den indekserer også databasen så den yder bedre.
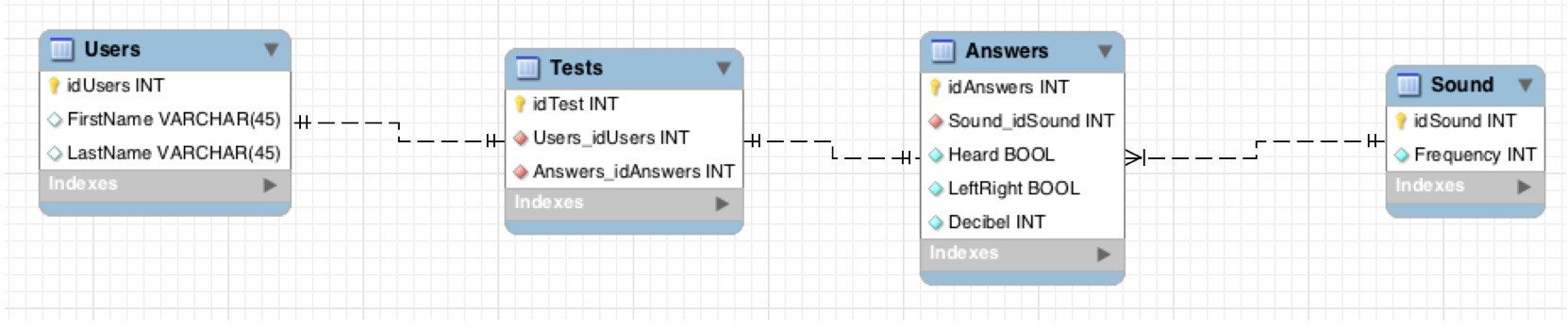
En tabel i vores diagram er ”Users” og en kolonne i denne tabel er ”Firstname”. Disse kolonner har fået tilføjet forskellige slags data typer. Data typer beskriver hvilke slags data der opbevares. Eksempler på data typer kan være tal, tegn eller datoer. Valg af korrekt datatype sørger for at værdier, der indsættes i databasen, giver mening og det sparer desuden plads (Wilton & Colby, side 18). De tilføjede data typer i vores diagram er ”VARCHAR(45)”, en tekst-streng på maks 45 tegn, ”INT” typen heltal, og ”BOOLEAN” typen true/false.
Diagrammet viser desuden relationen imellem tabellerne. I vores diagram ses flere en-en relationer og en relation bestående af en-mange eller en-en relation. Disse relationer viser hvor mange gange en forekomst (instance) i en tabel kan være forbundet med forekomsten (instance) i en relaterede tabel.
Det er værd at bemærke at idUsers (INT) er den værdi brugeren angiver som brugernavn i app’en, som han får tilsendt per brev fra sygehuset, hvor de andre id værdier er sat som AutoIncrement – at den automatisk sættes ind og øges med 1 for hvert nyt indlæg/række i tabellen.
Den gule nøgle viser at den række er sat til at være Primary Key.
Firkanterne viser forskellige information om de enkelte rækkers status: en hvid firkant viser at den ikke behøves være udfyldt, den blå at den skal være udfyldt (Not Null) og den røde at det er Foreign Keys, en værdi der er en primær-nøgle i en anden tabel.
Litteraturliste
- ANSI/ISO/IEC International Standard (IS). Database Language SQL—Part 2: Foundation (SQL/Foundation). 1999
- Boolsk algebra [hjemmeside] 06-12-2015
https://en.wikipedia.org/wiki/Boolean_algebra - Boyce–Codd normal formen [hjemmeside] 08-12-2015 https://en.wikipedia.org/wiki/Boyce–Codd_normal_form
- Churcher, Clare. 2012. Beginning Database Design: From Novice to Professional. 2nd Edition. New York: Apress.
- Join dependency. [hjemmeside] 10-12-2015.
https://en.wikipedia.org/wiki/Join_dependency - Larry Ellison [hjemmeside] 08-12-2015
https://en.wikipedia.org/wiki/Larry_Ellison - MySQL Enterprise Edition, Workbench. [Hjemmeside] 08-12-2015.
https://www.mysql.com/products/workbench/ - Oracle Database [hjemmeside] 08-12-2015
https://en.wikipedia.org/wiki/Oracle_Database - Sixth normal form. [hjemmeside] 10-12-2015.
https://en.wikipedia.org/wiki/Sixth_normal_form - SQL Joins. [hjemmeside] 09-12-2015.
http://www.w3schools.com/sql/sql_join.asp - The Database Normalization Process [hjemmeside] 09-12-2015
http://www.informit.com/articles/article.aspx?p=30646 - Three-valued logic [hjemmeside] 08-12-2015
https://en.wikipedia.org/wiki/Three-valued_logic - Visual representation of SQL Joins [hjemmeside] 10-12-2015
http://www.codeproject.com/Articles/33052/Visual-Representation-of-SQL-Joins - Wilton, Paul & Colby, John. 2005. Beginning SQL. Indianapolis: Wiley Publishing, Inc.
- Wilton side 7 ↩
- Boyce–Codd normal formen ↩
- Oracle Database ↩
- Larry Ellison ↩
- Three-valued logic ↩
- Boolsk Algebra ↩
- Wilton & Colby, kapitel 3 og 7 ↩
- Wilton & Colby, kap. 7 ↩
- SQL Joins ↩
- The Database Normalization Process ↩
- MySQL Enterprise Edition, Workbench ↩
- Join dependency ↩
- Sixth normal form ↩
- Churcher, kap. 7 ↩
Skriv et svar